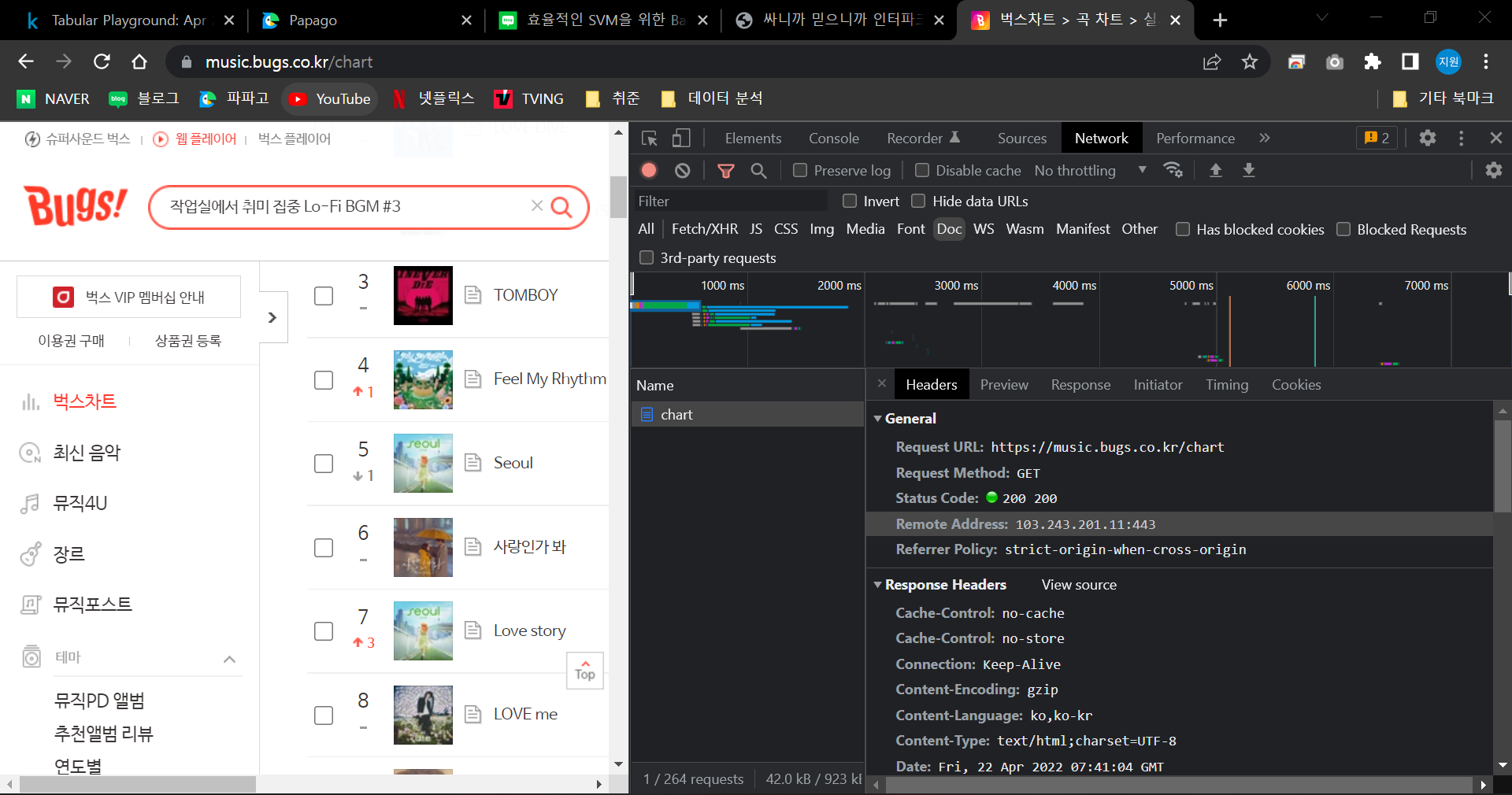
Website Info
Request URL : https://music.bugs.co.kr/chart
Request Method : GET
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.127 Safari/537.36
Crawling Code
step03_bugsTop100.py1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40import requests
import warnings
from bs4 import BeautifulSoup
warnings.filterwarnings('ignore')
import pandas as pd
def crawling(soup):
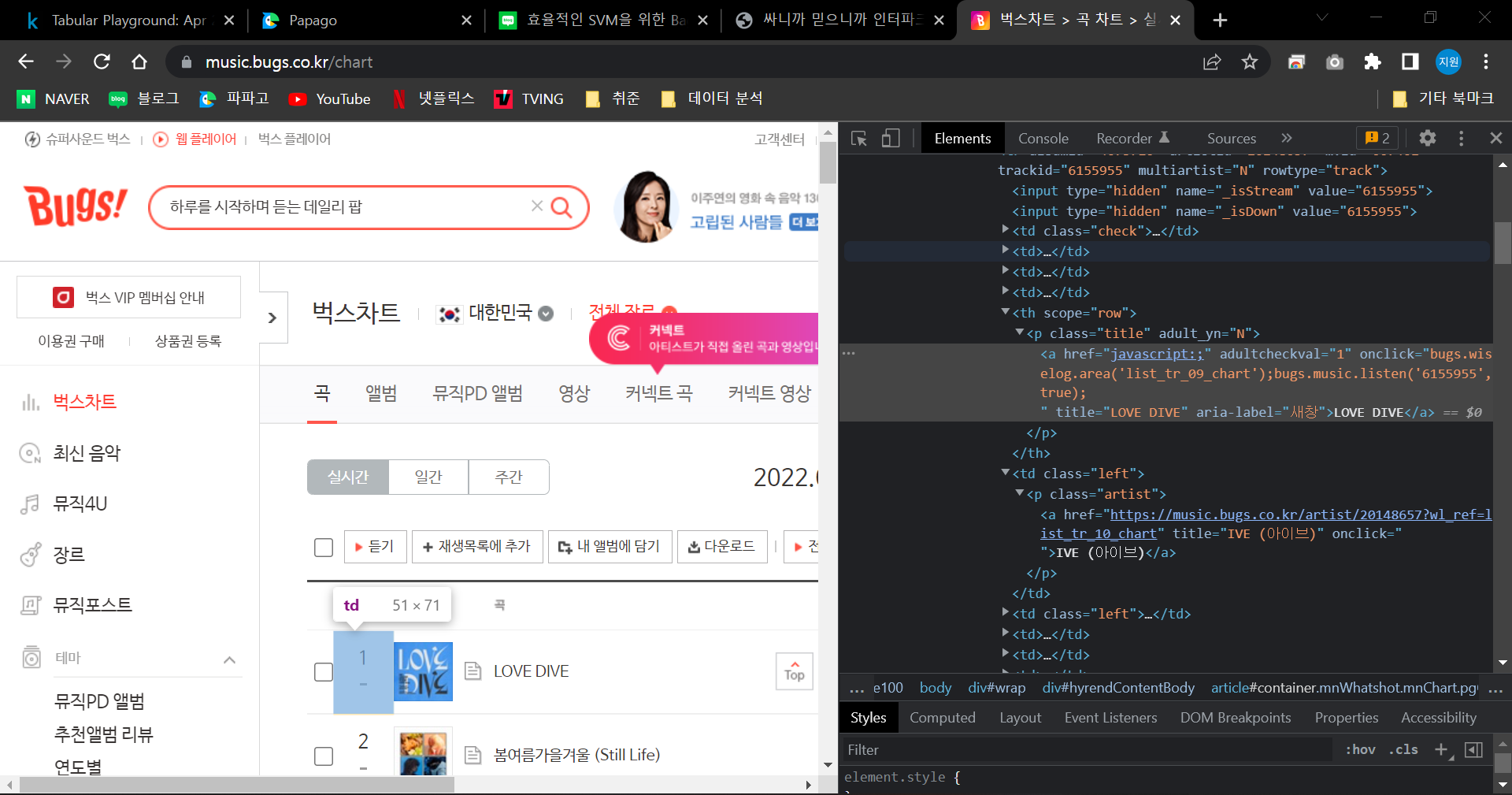
chart = soup.find("table", class_="list trackList byChart")
titles = []
artists = []
for p in chart.find_all("p", class_="title"):
titles.append(p.get_text()[1:-1])
for p in chart.find_all("p", class_="artist"):
artists.append(p.get_text()[1:-1])
return(titles, artists)
def df_csv(tp):
df = pd.DataFrame({"title" : tp[0], "artist" : tp[1]})
print(df)
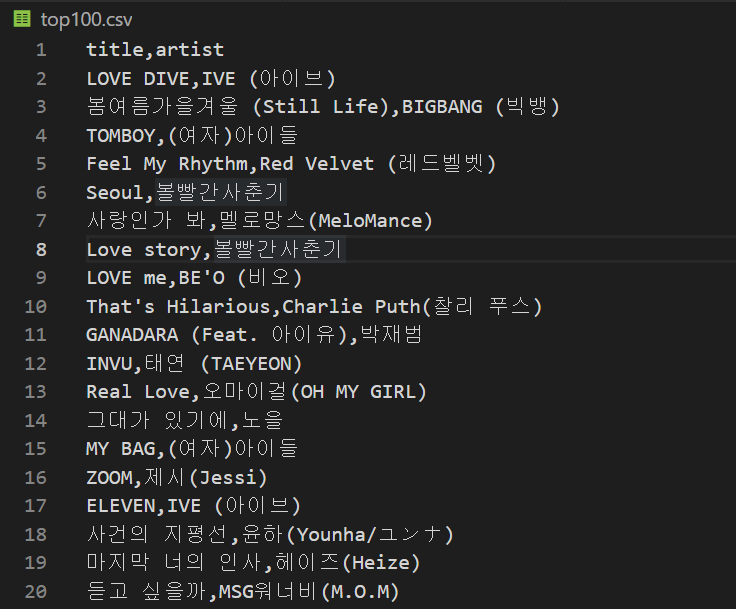
df.to_csv("top100.csv", index=False)
print("Crawling is done!")
def main():
CUSTOM_HEADER = {
'user-agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.127 Safari/537.36'
}
url = 'https://music.bugs.co.kr/chart'
req = requests.get(url = url, headers=CUSTOM_HEADER)
print(req.status_code)
soup = BeautifulSoup(req.text, 'html.parser')
print(type(soup))
df_csv(crawling(soup))
if __name__ == "__main__":
main()top100.csv