Check the Website Info
Access Developer Tools of the website and enter the Nework tab.
Type
ctrl + Rand enter the Doc tap.
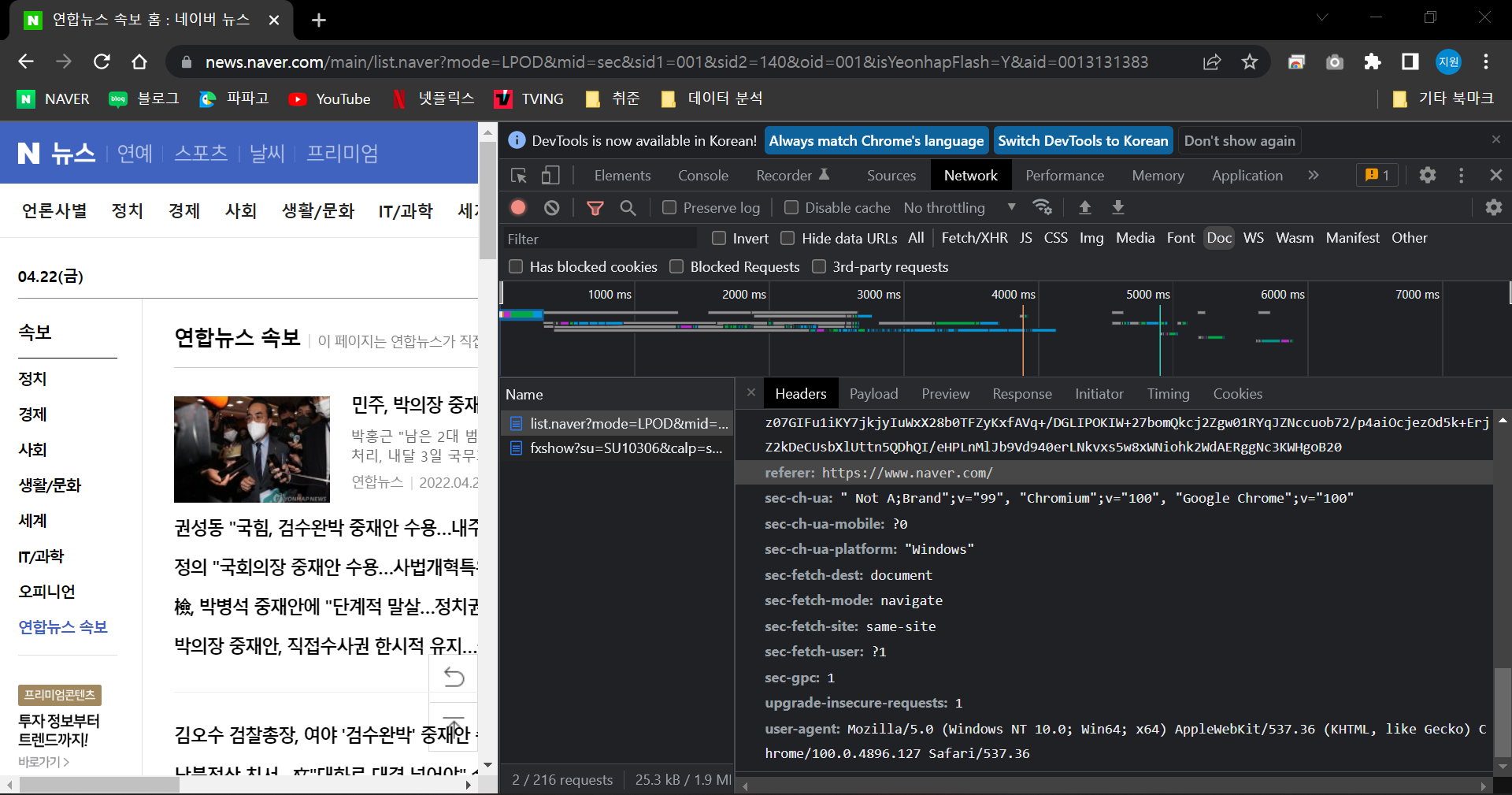
Enter a site and check the Headers tap with the site.
- Copy the value of referer and user-agent.
Crawling Code
step01_headlinenews.py1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45import warnings
import requests
from bs4 import BeautifulSoup
warnings.filterwarnings('ignore')
import pandas as pd
def crawling(soup):
div = soup.find("div", class_="list_issue")
print(type(div))
titles = []
urls = []
for a in div.find_all("a"):
titles.append(a.get_text())
urls.append(a['href'])
results = (titles, urls)
return(results)
def df_csv(tp):
df = pd.DataFrame({"newstitle" : tp[0], "url" : tp[1]})
print(df)
df.to_csv("headlinecrawling.csv", index=False)
print("Crawling is done!")
def main():
CUSTOM_HEADER = {
'referer' : 'https://www.naver.com/',
'user-agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.127 Safari/537.36'
}
url = 'https://www.naver.com/'
req = requests.get(url = url, headers=CUSTOM_HEADER)
print(req.status_code)
# 200 : Good
# 404 : URL Error
# 503 : Server Down
soup = BeautifulSoup(req.text, 'html.parser', from_encoding='utf-8')
df_csv(crawling(soup))
if __name__ == "__main__":
main()