LSTM(Long Short-Term Memory)
When the sentence is long, the learning ability of RNN is poor.
LSTM is designed to keep short-term memory long.
1 2 3 4 5 6 7 8 9 10 11 from tensorflow.keras.datasets import imdbfrom sklearn.model_selection import train_test_split(train_input, train_target), (test_input, test_target) = imdb.load_data( num_words=500 ) train_input, val_input, train_target, val_target = train_test_split( train_input, train_target, test_size=0.2 , random_state=42 ) train_input.shape, val_input.shape, train_target.shape, val_target.shape
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/imdb.npz
17465344/17464789 [==============================] - 0s 0us/step
17473536/17464789 [==============================] - 0s 0us/step
((20000,), (5000,), (20000,), (5000,))
1 2 3 4 5 from tensorflow.keras.preprocessing.sequence import pad_sequencestrain_seq = pad_sequences(train_input, maxlen=100 ) val_seq = pad_sequences(val_input, maxlen=100 ) train_seq.shape, val_seq.shape
((20000, 100), (5000, 100))
1 2 3 4 5 6 from tensorflow import kerasmodel = keras.Sequential() model.add(keras.layers.Embedding(500 , 16 , input_length=100 )) model.add(keras.layers.LSTM(8 )) model.add(keras.layers.Dense(1 , activation='sigmoid' )) model.summary()
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding (Embedding) (None, 100, 16) 8000
lstm (LSTM) (None, 8) 800
dense (Dense) (None, 1) 9
=================================================================
Total params: 8,809
Trainable params: 8,809
Non-trainable params: 0
_________________________________________________________________
1 2 3 4 5 6 7 8 9 10 11 12 rmsprop = keras.optimizers.RMSprop(learning_rate=1e-4 ) model.compile (optimizer=rmsprop, loss='binary_crossentropy' , metrics=['accuracy' ]) checkpoint_cb = keras.callbacks.ModelCheckpoint('best-lstm-model.h5' , save_best_only=True ) early_stopping_cb = keras.callbacks.EarlyStopping(patience=3 , restore_best_weights=True ) history = model.fit(train_seq, train_target, epochs=100 , batch_size=64 , validation_data=(val_seq, val_target), callbacks=[checkpoint_cb, early_stopping_cb])
Epoch 1/100
313/313 [==============================] - 16s 42ms/step - loss: 0.6925 - accuracy: 0.5433 - val_loss: 0.6916 - val_accuracy: 0.5986
Epoch 2/100
313/313 [==============================] - 20s 65ms/step - loss: 0.6902 - accuracy: 0.6076 - val_loss: 0.6883 - val_accuracy: 0.6470
Epoch 3/100
313/313 [==============================] - 16s 50ms/step - loss: 0.6842 - accuracy: 0.6512 - val_loss: 0.6783 - val_accuracy: 0.6680
Epoch 4/100
313/313 [==============================] - 14s 46ms/step - loss: 0.6591 - accuracy: 0.6861 - val_loss: 0.6237 - val_accuracy: 0.7128
Epoch 5/100
313/313 [==============================] - 14s 45ms/step - loss: 0.5975 - accuracy: 0.7211 - val_loss: 0.5842 - val_accuracy: 0.7220
Epoch 6/100
313/313 [==============================] - 16s 51ms/step - loss: 0.5716 - accuracy: 0.7355 - val_loss: 0.5643 - val_accuracy: 0.7408
Epoch 7/100
313/313 [==============================] - 14s 45ms/step - loss: 0.5510 - accuracy: 0.7534 - val_loss: 0.5470 - val_accuracy: 0.7458
Epoch 8/100
313/313 [==============================] - 17s 54ms/step - loss: 0.5328 - accuracy: 0.7619 - val_loss: 0.5319 - val_accuracy: 0.7564
Epoch 9/100
313/313 [==============================] - 14s 44ms/step - loss: 0.5147 - accuracy: 0.7739 - val_loss: 0.5130 - val_accuracy: 0.7724
Epoch 10/100
313/313 [==============================] - 13s 43ms/step - loss: 0.4982 - accuracy: 0.7824 - val_loss: 0.5000 - val_accuracy: 0.7746
Epoch 11/100
313/313 [==============================] - 17s 53ms/step - loss: 0.4837 - accuracy: 0.7909 - val_loss: 0.4874 - val_accuracy: 0.7794
Epoch 12/100
313/313 [==============================] - 15s 47ms/step - loss: 0.4717 - accuracy: 0.7957 - val_loss: 0.4767 - val_accuracy: 0.7868
Epoch 13/100
313/313 [==============================] - 13s 41ms/step - loss: 0.4620 - accuracy: 0.7990 - val_loss: 0.4696 - val_accuracy: 0.7892
Epoch 14/100
313/313 [==============================] - 15s 48ms/step - loss: 0.4534 - accuracy: 0.8033 - val_loss: 0.4662 - val_accuracy: 0.7908
Epoch 15/100
313/313 [==============================] - 15s 48ms/step - loss: 0.4470 - accuracy: 0.8067 - val_loss: 0.4606 - val_accuracy: 0.7946
Epoch 16/100
313/313 [==============================] - 15s 47ms/step - loss: 0.4414 - accuracy: 0.8067 - val_loss: 0.4558 - val_accuracy: 0.7924
Epoch 17/100
313/313 [==============================] - 14s 45ms/step - loss: 0.4366 - accuracy: 0.8087 - val_loss: 0.4516 - val_accuracy: 0.7972
Epoch 18/100
313/313 [==============================] - 12s 40ms/step - loss: 0.4329 - accuracy: 0.8098 - val_loss: 0.4485 - val_accuracy: 0.7968
Epoch 19/100
313/313 [==============================] - 12s 40ms/step - loss: 0.4301 - accuracy: 0.8088 - val_loss: 0.4461 - val_accuracy: 0.7962
Epoch 20/100
313/313 [==============================] - 12s 40ms/step - loss: 0.4274 - accuracy: 0.8093 - val_loss: 0.4456 - val_accuracy: 0.7988
Epoch 21/100
313/313 [==============================] - 12s 40ms/step - loss: 0.4248 - accuracy: 0.8102 - val_loss: 0.4429 - val_accuracy: 0.7994
Epoch 22/100
313/313 [==============================] - 13s 40ms/step - loss: 0.4225 - accuracy: 0.8106 - val_loss: 0.4481 - val_accuracy: 0.7960
Epoch 23/100
313/313 [==============================] - 12s 40ms/step - loss: 0.4211 - accuracy: 0.8117 - val_loss: 0.4417 - val_accuracy: 0.7974
Epoch 24/100
313/313 [==============================] - 12s 39ms/step - loss: 0.4198 - accuracy: 0.8116 - val_loss: 0.4393 - val_accuracy: 0.8010
Epoch 25/100
313/313 [==============================] - 13s 40ms/step - loss: 0.4180 - accuracy: 0.8127 - val_loss: 0.4464 - val_accuracy: 0.7890
Epoch 26/100
313/313 [==============================] - 13s 40ms/step - loss: 0.4173 - accuracy: 0.8130 - val_loss: 0.4400 - val_accuracy: 0.8002
Epoch 27/100
313/313 [==============================] - 12s 39ms/step - loss: 0.4161 - accuracy: 0.8123 - val_loss: 0.4370 - val_accuracy: 0.8018
Epoch 28/100
313/313 [==============================] - 12s 40ms/step - loss: 0.4154 - accuracy: 0.8131 - val_loss: 0.4375 - val_accuracy: 0.8010
Epoch 29/100
313/313 [==============================] - 13s 40ms/step - loss: 0.4143 - accuracy: 0.8127 - val_loss: 0.4361 - val_accuracy: 0.8020
Epoch 30/100
313/313 [==============================] - 14s 45ms/step - loss: 0.4131 - accuracy: 0.8136 - val_loss: 0.4370 - val_accuracy: 0.8022
Epoch 31/100
313/313 [==============================] - 13s 40ms/step - loss: 0.4129 - accuracy: 0.8134 - val_loss: 0.4360 - val_accuracy: 0.8022
Epoch 32/100
313/313 [==============================] - 13s 40ms/step - loss: 0.4126 - accuracy: 0.8141 - val_loss: 0.4355 - val_accuracy: 0.8014
Epoch 33/100
313/313 [==============================] - 12s 39ms/step - loss: 0.4117 - accuracy: 0.8134 - val_loss: 0.4358 - val_accuracy: 0.8040
Epoch 34/100
313/313 [==============================] - 13s 41ms/step - loss: 0.4112 - accuracy: 0.8134 - val_loss: 0.4346 - val_accuracy: 0.7986
Epoch 35/100
313/313 [==============================] - 12s 40ms/step - loss: 0.4106 - accuracy: 0.8134 - val_loss: 0.4353 - val_accuracy: 0.7978
Epoch 36/100
313/313 [==============================] - 13s 40ms/step - loss: 0.4100 - accuracy: 0.8144 - val_loss: 0.4346 - val_accuracy: 0.7976
Epoch 37/100
313/313 [==============================] - 12s 39ms/step - loss: 0.4100 - accuracy: 0.8128 - val_loss: 0.4342 - val_accuracy: 0.8052
Epoch 38/100
313/313 [==============================] - 12s 40ms/step - loss: 0.4092 - accuracy: 0.8141 - val_loss: 0.4350 - val_accuracy: 0.8052
Epoch 39/100
313/313 [==============================] - 12s 40ms/step - loss: 0.4090 - accuracy: 0.8138 - val_loss: 0.4334 - val_accuracy: 0.8028
Epoch 40/100
313/313 [==============================] - 13s 40ms/step - loss: 0.4083 - accuracy: 0.8152 - val_loss: 0.4325 - val_accuracy: 0.7992
Epoch 41/100
313/313 [==============================] - 12s 40ms/step - loss: 0.4080 - accuracy: 0.8156 - val_loss: 0.4358 - val_accuracy: 0.7960
Epoch 42/100
313/313 [==============================] - 12s 40ms/step - loss: 0.4075 - accuracy: 0.8149 - val_loss: 0.4322 - val_accuracy: 0.8016
Epoch 43/100
313/313 [==============================] - 12s 39ms/step - loss: 0.4069 - accuracy: 0.8134 - val_loss: 0.4327 - val_accuracy: 0.8014
Epoch 44/100
313/313 [==============================] - 12s 40ms/step - loss: 0.4067 - accuracy: 0.8155 - val_loss: 0.4333 - val_accuracy: 0.8042
Epoch 45/100
313/313 [==============================] - 12s 40ms/step - loss: 0.4063 - accuracy: 0.8140 - val_loss: 0.4331 - val_accuracy: 0.8022
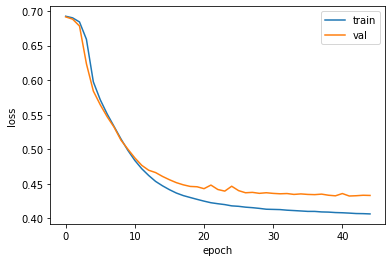
1 2 3 4 5 6 7 8 import matplotlib.pyplot as pltfig, ax = plt.subplots() ax.plot(history.history['loss' ]) ax.plot(history.history['val_loss' ]) ax.set_xlabel('epoch' ) ax.set_ylabel('loss' ) ax.legend(['train' , 'val' ]) plt.show()
1 2 3 4 5 model2 = keras.Sequential() model2.add(keras.layers.Embedding(500 , 16 , input_length=100 )) model2.add(keras.layers.LSTM(8 , dropout=0.3 )) model2.add(keras.layers.Dense(1 , activation='sigmoid' )) model2.summary()
Model: "sequential_1"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding_1 (Embedding) (None, 100, 16) 8000
lstm_1 (LSTM) (None, 8) 800
dense_1 (Dense) (None, 1) 9
=================================================================
Total params: 8,809
Trainable params: 8,809
Non-trainable params: 0
_________________________________________________________________
1 2 3 4 5 6 7 8 9 10 11 12 rmsprop = keras.optimizers.RMSprop(learning_rate=1e-4 ) model2.compile (optimizer=rmsprop, loss='binary_crossentropy' , metrics=['accuracy' ]) checkpoint_cb = keras.callbacks.ModelCheckpoint('best-dropout-model.h5' , save_best_only=True ) early_stopping_cb = keras.callbacks.EarlyStopping(patience=3 , restore_best_weights=True ) history = model2.fit(train_seq, train_target, epochs=100 , batch_size=64 , validation_data=(val_seq, val_target), callbacks=[checkpoint_cb, early_stopping_cb])
Epoch 1/100
313/313 [==============================] - 18s 48ms/step - loss: 0.6925 - accuracy: 0.5239 - val_loss: 0.6913 - val_accuracy: 0.5654
Epoch 2/100
313/313 [==============================] - 13s 42ms/step - loss: 0.6895 - accuracy: 0.5954 - val_loss: 0.6872 - val_accuracy: 0.6314
Epoch 3/100
313/313 [==============================] - 13s 42ms/step - loss: 0.6816 - accuracy: 0.6561 - val_loss: 0.6736 - val_accuracy: 0.6828
Epoch 4/100
313/313 [==============================] - 13s 42ms/step - loss: 0.6444 - accuracy: 0.7018 - val_loss: 0.6027 - val_accuracy: 0.7116
Epoch 5/100
313/313 [==============================] - 13s 43ms/step - loss: 0.5789 - accuracy: 0.7199 - val_loss: 0.5620 - val_accuracy: 0.7352
Epoch 6/100
313/313 [==============================] - 14s 44ms/step - loss: 0.5517 - accuracy: 0.7405 - val_loss: 0.5403 - val_accuracy: 0.7526
Epoch 7/100
313/313 [==============================] - 14s 44ms/step - loss: 0.5317 - accuracy: 0.7545 - val_loss: 0.5219 - val_accuracy: 0.7598
Epoch 8/100
313/313 [==============================] - 13s 43ms/step - loss: 0.5117 - accuracy: 0.7681 - val_loss: 0.5049 - val_accuracy: 0.7702
Epoch 9/100
313/313 [==============================] - 14s 43ms/step - loss: 0.4968 - accuracy: 0.7747 - val_loss: 0.4917 - val_accuracy: 0.7760
Epoch 10/100
313/313 [==============================] - 13s 42ms/step - loss: 0.4844 - accuracy: 0.7829 - val_loss: 0.4814 - val_accuracy: 0.7864
Epoch 11/100
313/313 [==============================] - 13s 42ms/step - loss: 0.4741 - accuracy: 0.7871 - val_loss: 0.4728 - val_accuracy: 0.7892
Epoch 12/100
313/313 [==============================] - 13s 42ms/step - loss: 0.4667 - accuracy: 0.7912 - val_loss: 0.4679 - val_accuracy: 0.7870
Epoch 13/100
313/313 [==============================] - 13s 42ms/step - loss: 0.4584 - accuracy: 0.7942 - val_loss: 0.4614 - val_accuracy: 0.7932
Epoch 14/100
313/313 [==============================] - 13s 42ms/step - loss: 0.4530 - accuracy: 0.7968 - val_loss: 0.4590 - val_accuracy: 0.7942
Epoch 15/100
313/313 [==============================] - 13s 42ms/step - loss: 0.4499 - accuracy: 0.7979 - val_loss: 0.4546 - val_accuracy: 0.7956
Epoch 16/100
313/313 [==============================] - 13s 42ms/step - loss: 0.4458 - accuracy: 0.7995 - val_loss: 0.4517 - val_accuracy: 0.7988
Epoch 17/100
313/313 [==============================] - 13s 42ms/step - loss: 0.4415 - accuracy: 0.7990 - val_loss: 0.4481 - val_accuracy: 0.7984
Epoch 18/100
313/313 [==============================] - 13s 41ms/step - loss: 0.4374 - accuracy: 0.8018 - val_loss: 0.4468 - val_accuracy: 0.7994
Epoch 19/100
313/313 [==============================] - 13s 41ms/step - loss: 0.4342 - accuracy: 0.8030 - val_loss: 0.4516 - val_accuracy: 0.7964
Epoch 20/100
313/313 [==============================] - 13s 41ms/step - loss: 0.4325 - accuracy: 0.8054 - val_loss: 0.4431 - val_accuracy: 0.8024
Epoch 21/100
313/313 [==============================] - 13s 42ms/step - loss: 0.4305 - accuracy: 0.8057 - val_loss: 0.4400 - val_accuracy: 0.7996
Epoch 22/100
313/313 [==============================] - 13s 41ms/step - loss: 0.4279 - accuracy: 0.8037 - val_loss: 0.4388 - val_accuracy: 0.7964
Epoch 23/100
313/313 [==============================] - 13s 41ms/step - loss: 0.4250 - accuracy: 0.8075 - val_loss: 0.4392 - val_accuracy: 0.8014
Epoch 24/100
313/313 [==============================] - 13s 41ms/step - loss: 0.4253 - accuracy: 0.8062 - val_loss: 0.4361 - val_accuracy: 0.7966
Epoch 25/100
313/313 [==============================] - 13s 41ms/step - loss: 0.4241 - accuracy: 0.8077 - val_loss: 0.4357 - val_accuracy: 0.8008
Epoch 26/100
313/313 [==============================] - 13s 42ms/step - loss: 0.4219 - accuracy: 0.8077 - val_loss: 0.4342 - val_accuracy: 0.8008
Epoch 27/100
313/313 [==============================] - 13s 41ms/step - loss: 0.4205 - accuracy: 0.8097 - val_loss: 0.4331 - val_accuracy: 0.8002
Epoch 28/100
313/313 [==============================] - 13s 42ms/step - loss: 0.4195 - accuracy: 0.8098 - val_loss: 0.4327 - val_accuracy: 0.7988
Epoch 29/100
313/313 [==============================] - 13s 41ms/step - loss: 0.4197 - accuracy: 0.8058 - val_loss: 0.4326 - val_accuracy: 0.8006
Epoch 30/100
313/313 [==============================] - 13s 42ms/step - loss: 0.4172 - accuracy: 0.8076 - val_loss: 0.4335 - val_accuracy: 0.7954
Epoch 31/100
313/313 [==============================] - 13s 42ms/step - loss: 0.4160 - accuracy: 0.8116 - val_loss: 0.4308 - val_accuracy: 0.8012
Epoch 32/100
313/313 [==============================] - 13s 42ms/step - loss: 0.4161 - accuracy: 0.8108 - val_loss: 0.4319 - val_accuracy: 0.7986
Epoch 33/100
313/313 [==============================] - 13s 42ms/step - loss: 0.4140 - accuracy: 0.8119 - val_loss: 0.4304 - val_accuracy: 0.8006
Epoch 34/100
313/313 [==============================] - 13s 42ms/step - loss: 0.4146 - accuracy: 0.8110 - val_loss: 0.4299 - val_accuracy: 0.7984
Epoch 35/100
313/313 [==============================] - 13s 42ms/step - loss: 0.4140 - accuracy: 0.8101 - val_loss: 0.4293 - val_accuracy: 0.8008
Epoch 36/100
313/313 [==============================] - 13s 41ms/step - loss: 0.4132 - accuracy: 0.8122 - val_loss: 0.4293 - val_accuracy: 0.7994
Epoch 37/100
313/313 [==============================] - 13s 41ms/step - loss: 0.4127 - accuracy: 0.8110 - val_loss: 0.4307 - val_accuracy: 0.7980
Epoch 38/100
313/313 [==============================] - 13s 42ms/step - loss: 0.4137 - accuracy: 0.8112 - val_loss: 0.4286 - val_accuracy: 0.8046
Epoch 39/100
313/313 [==============================] - 13s 42ms/step - loss: 0.4127 - accuracy: 0.8109 - val_loss: 0.4277 - val_accuracy: 0.8040
Epoch 40/100
313/313 [==============================] - 13s 41ms/step - loss: 0.4103 - accuracy: 0.8106 - val_loss: 0.4284 - val_accuracy: 0.8052
Epoch 41/100
313/313 [==============================] - 13s 41ms/step - loss: 0.4105 - accuracy: 0.8106 - val_loss: 0.4281 - val_accuracy: 0.8002
Epoch 42/100
313/313 [==============================] - 13s 41ms/step - loss: 0.4111 - accuracy: 0.8137 - val_loss: 0.4284 - val_accuracy: 0.7982
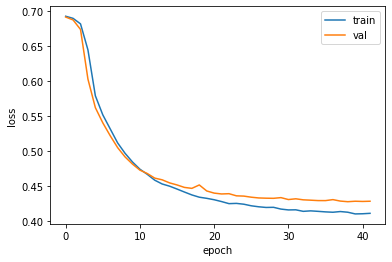
1 2 3 4 5 6 7 fig, ax = plt.subplots() ax.plot(history.history['loss' ]) ax.plot(history.history['val_loss' ]) ax.set_xlabel('epoch' ) ax.set_ylabel('loss' ) ax.legend(['train' , 'val' ]) plt.show()
1 2 3 4 5 6 model3 = keras.Sequential() model3.add(keras.layers.Embedding(500 , 16 , input_length=100 )) model3.add(keras.layers.LSTM(8 , dropout=0.3 , return_sequences=True )) model3.add(keras.layers.LSTM(8 , dropout=0.3 )) model3.add(keras.layers.Dense(1 , activation='sigmoid' )) model3.summary()
Model: "sequential_2"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding_2 (Embedding) (None, 100, 16) 8000
lstm_2 (LSTM) (None, 100, 8) 800
lstm_3 (LSTM) (None, 8) 544
dense_2 (Dense) (None, 1) 9
=================================================================
Total params: 9,353
Trainable params: 9,353
Non-trainable params: 0
_________________________________________________________________
1 2 3 4 5 6 7 8 9 10 11 12 rmsprop = keras.optimizers.RMSprop(learning_rate=1e-4 ) model3.compile (optimizer=rmsprop, loss='binary_crossentropy' , metrics=['accuracy' ]) checkpoint_cb = keras.callbacks.ModelCheckpoint('best-2rnn-model.h5' , save_best_only=True ) early_stopping_cb = keras.callbacks.EarlyStopping(patience=3 , restore_best_weights=True ) history = model3.fit(train_seq, train_target, epochs=100 , batch_size=64 , validation_data=(val_seq, val_target), callbacks=[checkpoint_cb, early_stopping_cb])
Epoch 1/100
313/313 [==============================] - 29s 81ms/step - loss: 0.6908 - accuracy: 0.5653 - val_loss: 0.6870 - val_accuracy: 0.6378
Epoch 2/100
313/313 [==============================] - 25s 79ms/step - loss: 0.6632 - accuracy: 0.6561 - val_loss: 0.6162 - val_accuracy: 0.6984
Epoch 3/100
313/313 [==============================] - 24s 78ms/step - loss: 0.5830 - accuracy: 0.7079 - val_loss: 0.5565 - val_accuracy: 0.7352
Epoch 4/100
313/313 [==============================] - 24s 78ms/step - loss: 0.5463 - accuracy: 0.7387 - val_loss: 0.5279 - val_accuracy: 0.7536
Epoch 5/100
313/313 [==============================] - 25s 79ms/step - loss: 0.5207 - accuracy: 0.7556 - val_loss: 0.5072 - val_accuracy: 0.7636
Epoch 6/100
313/313 [==============================] - 25s 79ms/step - loss: 0.5026 - accuracy: 0.7671 - val_loss: 0.4941 - val_accuracy: 0.7730
Epoch 7/100
313/313 [==============================] - 25s 79ms/step - loss: 0.4910 - accuracy: 0.7728 - val_loss: 0.4812 - val_accuracy: 0.7818
Epoch 8/100
313/313 [==============================] - 31s 100ms/step - loss: 0.4813 - accuracy: 0.7782 - val_loss: 0.4747 - val_accuracy: 0.7810
Epoch 9/100
313/313 [==============================] - 25s 79ms/step - loss: 0.4730 - accuracy: 0.7832 - val_loss: 0.4661 - val_accuracy: 0.7878
Epoch 10/100
313/313 [==============================] - 25s 79ms/step - loss: 0.4657 - accuracy: 0.7869 - val_loss: 0.4612 - val_accuracy: 0.7896
Epoch 11/100
313/313 [==============================] - 25s 78ms/step - loss: 0.4614 - accuracy: 0.7872 - val_loss: 0.4589 - val_accuracy: 0.7898
Epoch 12/100
313/313 [==============================] - 24s 78ms/step - loss: 0.4568 - accuracy: 0.7886 - val_loss: 0.4547 - val_accuracy: 0.7934
Epoch 13/100
313/313 [==============================] - 24s 78ms/step - loss: 0.4519 - accuracy: 0.7911 - val_loss: 0.4577 - val_accuracy: 0.7874
Epoch 14/100
313/313 [==============================] - 24s 78ms/step - loss: 0.4484 - accuracy: 0.7945 - val_loss: 0.4498 - val_accuracy: 0.7930
Epoch 15/100
313/313 [==============================] - 25s 78ms/step - loss: 0.4472 - accuracy: 0.7955 - val_loss: 0.4498 - val_accuracy: 0.7914
Epoch 16/100
313/313 [==============================] - 24s 78ms/step - loss: 0.4447 - accuracy: 0.7983 - val_loss: 0.4468 - val_accuracy: 0.7968
Epoch 17/100
313/313 [==============================] - 25s 78ms/step - loss: 0.4441 - accuracy: 0.7944 - val_loss: 0.4444 - val_accuracy: 0.7968
Epoch 18/100
313/313 [==============================] - 24s 78ms/step - loss: 0.4418 - accuracy: 0.7990 - val_loss: 0.4442 - val_accuracy: 0.7950
Epoch 19/100
313/313 [==============================] - 24s 78ms/step - loss: 0.4375 - accuracy: 0.8007 - val_loss: 0.4477 - val_accuracy: 0.7936
Epoch 20/100
313/313 [==============================] - 25s 79ms/step - loss: 0.4365 - accuracy: 0.8027 - val_loss: 0.4416 - val_accuracy: 0.7964
Epoch 21/100
313/313 [==============================] - 25s 79ms/step - loss: 0.4354 - accuracy: 0.8012 - val_loss: 0.4415 - val_accuracy: 0.7944
Epoch 22/100
313/313 [==============================] - 24s 78ms/step - loss: 0.4341 - accuracy: 0.8014 - val_loss: 0.4408 - val_accuracy: 0.7972
Epoch 23/100
313/313 [==============================] - 24s 78ms/step - loss: 0.4345 - accuracy: 0.8008 - val_loss: 0.4390 - val_accuracy: 0.7960
Epoch 24/100
313/313 [==============================] - 24s 78ms/step - loss: 0.4315 - accuracy: 0.8037 - val_loss: 0.4412 - val_accuracy: 0.7912
Epoch 25/100
313/313 [==============================] - 24s 78ms/step - loss: 0.4305 - accuracy: 0.8049 - val_loss: 0.4397 - val_accuracy: 0.7928
Epoch 26/100
313/313 [==============================] - 24s 78ms/step - loss: 0.4294 - accuracy: 0.8051 - val_loss: 0.4382 - val_accuracy: 0.7990
Epoch 27/100
313/313 [==============================] - 24s 78ms/step - loss: 0.4281 - accuracy: 0.8025 - val_loss: 0.4378 - val_accuracy: 0.7954
Epoch 28/100
313/313 [==============================] - 24s 78ms/step - loss: 0.4277 - accuracy: 0.8035 - val_loss: 0.4375 - val_accuracy: 0.7952
Epoch 29/100
313/313 [==============================] - 25s 78ms/step - loss: 0.4255 - accuracy: 0.8067 - val_loss: 0.4365 - val_accuracy: 0.7984
Epoch 30/100
313/313 [==============================] - 25s 79ms/step - loss: 0.4254 - accuracy: 0.8055 - val_loss: 0.4360 - val_accuracy: 0.7990
Epoch 31/100
313/313 [==============================] - 25s 78ms/step - loss: 0.4248 - accuracy: 0.8065 - val_loss: 0.4350 - val_accuracy: 0.8000
Epoch 32/100
313/313 [==============================] - 25s 79ms/step - loss: 0.4247 - accuracy: 0.8051 - val_loss: 0.4352 - val_accuracy: 0.8006
Epoch 33/100
313/313 [==============================] - 25s 80ms/step - loss: 0.4240 - accuracy: 0.8061 - val_loss: 0.4358 - val_accuracy: 0.7958
Epoch 34/100
313/313 [==============================] - 25s 79ms/step - loss: 0.4239 - accuracy: 0.8051 - val_loss: 0.4348 - val_accuracy: 0.8020
Epoch 35/100
313/313 [==============================] - 25s 79ms/step - loss: 0.4240 - accuracy: 0.8066 - val_loss: 0.4340 - val_accuracy: 0.7998
Epoch 36/100
313/313 [==============================] - 24s 78ms/step - loss: 0.4230 - accuracy: 0.8044 - val_loss: 0.4358 - val_accuracy: 0.8024
Epoch 37/100
313/313 [==============================] - 25s 78ms/step - loss: 0.4227 - accuracy: 0.8061 - val_loss: 0.4334 - val_accuracy: 0.7994
Epoch 38/100
313/313 [==============================] - 25s 79ms/step - loss: 0.4207 - accuracy: 0.8063 - val_loss: 0.4337 - val_accuracy: 0.8000
Epoch 39/100
313/313 [==============================] - 25s 79ms/step - loss: 0.4194 - accuracy: 0.8075 - val_loss: 0.4349 - val_accuracy: 0.8012
Epoch 40/100
313/313 [==============================] - 25s 80ms/step - loss: 0.4203 - accuracy: 0.8073 - val_loss: 0.4326 - val_accuracy: 0.8018
Epoch 41/100
313/313 [==============================] - 25s 79ms/step - loss: 0.4208 - accuracy: 0.8064 - val_loss: 0.4347 - val_accuracy: 0.8036
Epoch 42/100
313/313 [==============================] - 25s 80ms/step - loss: 0.4196 - accuracy: 0.8066 - val_loss: 0.4371 - val_accuracy: 0.8006
Epoch 43/100
313/313 [==============================] - 25s 79ms/step - loss: 0.4196 - accuracy: 0.8066 - val_loss: 0.4358 - val_accuracy: 0.8018
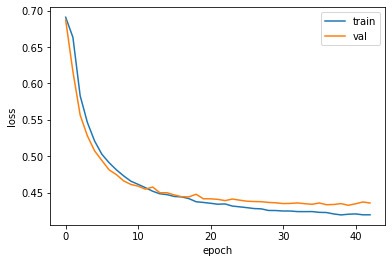
1 2 3 4 5 6 7 fig, ax = plt.subplots() ax.plot(history.history['loss' ]) ax.plot(history.history['val_loss' ]) ax.set_xlabel('epoch' ) ax.set_ylabel('loss' ) ax.legend(['train' , 'val' ]) plt.show()
GRU(Gated Recurrent Unit)
1 2 3 4 5 model4 = keras.Sequential() model4.add(keras.layers.Embedding(500 , 16 , input_length=100 )) model4.add(keras.layers.GRU(8 )) model4.add(keras.layers.Dense(1 , activation='sigmoid' )) model4.summary()
Model: "sequential_3"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding_3 (Embedding) (None, 100, 16) 8000
gru (GRU) (None, 8) 624
dense_3 (Dense) (None, 1) 9
=================================================================
Total params: 8,633
Trainable params: 8,633
Non-trainable params: 0
_________________________________________________________________
1 2 3 4 5 6 7 8 9 10 11 12 rmsprop = keras.optimizers.RMSprop(learning_rate=1e-4 ) model4.compile (optimizer=rmsprop, loss='binary_crossentropy' , metrics=['accuracy' ]) checkpoint_cb = keras.callbacks.ModelCheckpoint('best-gru-model.h5' , save_best_only=True ) early_stopping_cb = keras.callbacks.EarlyStopping(patience=3 , restore_best_weights=True ) history = model4.fit(train_seq, train_target, epochs=100 , batch_size=64 , validation_data=(val_seq, val_target), callbacks=[checkpoint_cb, early_stopping_cb])
Epoch 1/100
313/313 [==============================] - 16s 45ms/step - loss: 0.6925 - accuracy: 0.5303 - val_loss: 0.6916 - val_accuracy: 0.5616
Epoch 2/100
313/313 [==============================] - 13s 43ms/step - loss: 0.6905 - accuracy: 0.5642 - val_loss: 0.6895 - val_accuracy: 0.5804
Epoch 3/100
313/313 [==============================] - 13s 43ms/step - loss: 0.6875 - accuracy: 0.5913 - val_loss: 0.6861 - val_accuracy: 0.5956
Epoch 4/100
313/313 [==============================] - 14s 43ms/step - loss: 0.6826 - accuracy: 0.6100 - val_loss: 0.6803 - val_accuracy: 0.6116
Epoch 5/100
313/313 [==============================] - 13s 42ms/step - loss: 0.6747 - accuracy: 0.6278 - val_loss: 0.6712 - val_accuracy: 0.6314
Epoch 6/100
313/313 [==============================] - 13s 43ms/step - loss: 0.6611 - accuracy: 0.6477 - val_loss: 0.6548 - val_accuracy: 0.6538
Epoch 7/100
313/313 [==============================] - 13s 42ms/step - loss: 0.6369 - accuracy: 0.6689 - val_loss: 0.6239 - val_accuracy: 0.6790
Epoch 8/100
313/313 [==============================] - 13s 42ms/step - loss: 0.5868 - accuracy: 0.7036 - val_loss: 0.5557 - val_accuracy: 0.7230
Epoch 9/100
313/313 [==============================] - 13s 42ms/step - loss: 0.5165 - accuracy: 0.7487 - val_loss: 0.5120 - val_accuracy: 0.7520
Epoch 10/100
313/313 [==============================] - 13s 43ms/step - loss: 0.4907 - accuracy: 0.7675 - val_loss: 0.4945 - val_accuracy: 0.7624
Epoch 11/100
313/313 [==============================] - 14s 43ms/step - loss: 0.4746 - accuracy: 0.7786 - val_loss: 0.4819 - val_accuracy: 0.7712
Epoch 12/100
313/313 [==============================] - 13s 43ms/step - loss: 0.4622 - accuracy: 0.7870 - val_loss: 0.4729 - val_accuracy: 0.7780
Epoch 13/100
313/313 [==============================] - 13s 42ms/step - loss: 0.4530 - accuracy: 0.7927 - val_loss: 0.4647 - val_accuracy: 0.7824
Epoch 14/100
313/313 [==============================] - 13s 42ms/step - loss: 0.4451 - accuracy: 0.7976 - val_loss: 0.4613 - val_accuracy: 0.7862
Epoch 15/100
313/313 [==============================] - 13s 43ms/step - loss: 0.4388 - accuracy: 0.8009 - val_loss: 0.4538 - val_accuracy: 0.7864
Epoch 16/100
313/313 [==============================] - 13s 43ms/step - loss: 0.4342 - accuracy: 0.8044 - val_loss: 0.4503 - val_accuracy: 0.7912
Epoch 17/100
313/313 [==============================] - 13s 42ms/step - loss: 0.4302 - accuracy: 0.8057 - val_loss: 0.4499 - val_accuracy: 0.7906
Epoch 18/100
313/313 [==============================] - 13s 43ms/step - loss: 0.4265 - accuracy: 0.8094 - val_loss: 0.4460 - val_accuracy: 0.7964
Epoch 19/100
313/313 [==============================] - 13s 43ms/step - loss: 0.4239 - accuracy: 0.8113 - val_loss: 0.4442 - val_accuracy: 0.7972
Epoch 20/100
313/313 [==============================] - 13s 43ms/step - loss: 0.4214 - accuracy: 0.8130 - val_loss: 0.4434 - val_accuracy: 0.7978
Epoch 21/100
313/313 [==============================] - 13s 42ms/step - loss: 0.4195 - accuracy: 0.8127 - val_loss: 0.4436 - val_accuracy: 0.7994
Epoch 22/100
313/313 [==============================] - 13s 42ms/step - loss: 0.4180 - accuracy: 0.8145 - val_loss: 0.4415 - val_accuracy: 0.7968
Epoch 23/100
313/313 [==============================] - 13s 42ms/step - loss: 0.4164 - accuracy: 0.8141 - val_loss: 0.4401 - val_accuracy: 0.8006
Epoch 24/100
313/313 [==============================] - 14s 43ms/step - loss: 0.4151 - accuracy: 0.8149 - val_loss: 0.4401 - val_accuracy: 0.7978
Epoch 25/100
313/313 [==============================] - 14s 43ms/step - loss: 0.4136 - accuracy: 0.8159 - val_loss: 0.4398 - val_accuracy: 0.7988
Epoch 26/100
313/313 [==============================] - 13s 43ms/step - loss: 0.4128 - accuracy: 0.8171 - val_loss: 0.4394 - val_accuracy: 0.7962
Epoch 27/100
313/313 [==============================] - 13s 43ms/step - loss: 0.4116 - accuracy: 0.8181 - val_loss: 0.4384 - val_accuracy: 0.7980
Epoch 28/100
313/313 [==============================] - 14s 43ms/step - loss: 0.4111 - accuracy: 0.8163 - val_loss: 0.4378 - val_accuracy: 0.8012
Epoch 29/100
313/313 [==============================] - 14s 43ms/step - loss: 0.4102 - accuracy: 0.8189 - val_loss: 0.4378 - val_accuracy: 0.7974
Epoch 30/100
313/313 [==============================] - 13s 43ms/step - loss: 0.4096 - accuracy: 0.8183 - val_loss: 0.4380 - val_accuracy: 0.7978
Epoch 31/100
313/313 [==============================] - 13s 43ms/step - loss: 0.4087 - accuracy: 0.8187 - val_loss: 0.4376 - val_accuracy: 0.7978
Epoch 32/100
313/313 [==============================] - 13s 43ms/step - loss: 0.4080 - accuracy: 0.8183 - val_loss: 0.4387 - val_accuracy: 0.7976
Epoch 33/100
313/313 [==============================] - 13s 43ms/step - loss: 0.4076 - accuracy: 0.8184 - val_loss: 0.4352 - val_accuracy: 0.8018
Epoch 34/100
313/313 [==============================] - 13s 42ms/step - loss: 0.4065 - accuracy: 0.8183 - val_loss: 0.4359 - val_accuracy: 0.7948
Epoch 35/100
313/313 [==============================] - 13s 43ms/step - loss: 0.4060 - accuracy: 0.8185 - val_loss: 0.4350 - val_accuracy: 0.7974
Epoch 36/100
313/313 [==============================] - 13s 43ms/step - loss: 0.4059 - accuracy: 0.8194 - val_loss: 0.4426 - val_accuracy: 0.7946
Epoch 37/100
313/313 [==============================] - 13s 43ms/step - loss: 0.4048 - accuracy: 0.8208 - val_loss: 0.4329 - val_accuracy: 0.8018
Epoch 38/100
313/313 [==============================] - 13s 43ms/step - loss: 0.4044 - accuracy: 0.8197 - val_loss: 0.4335 - val_accuracy: 0.7998
Epoch 39/100
313/313 [==============================] - 13s 43ms/step - loss: 0.4040 - accuracy: 0.8202 - val_loss: 0.4327 - val_accuracy: 0.8010
Epoch 40/100
313/313 [==============================] - 13s 43ms/step - loss: 0.4039 - accuracy: 0.8199 - val_loss: 0.4325 - val_accuracy: 0.8042
Epoch 41/100
313/313 [==============================] - 13s 43ms/step - loss: 0.4031 - accuracy: 0.8197 - val_loss: 0.4316 - val_accuracy: 0.8024
Epoch 42/100
313/313 [==============================] - 13s 43ms/step - loss: 0.4025 - accuracy: 0.8213 - val_loss: 0.4316 - val_accuracy: 0.8004
Epoch 43/100
313/313 [==============================] - 13s 43ms/step - loss: 0.4020 - accuracy: 0.8198 - val_loss: 0.4320 - val_accuracy: 0.7986
Epoch 44/100
313/313 [==============================] - 13s 43ms/step - loss: 0.4016 - accuracy: 0.8214 - val_loss: 0.4311 - val_accuracy: 0.8020
Epoch 45/100
313/313 [==============================] - 13s 43ms/step - loss: 0.4011 - accuracy: 0.8214 - val_loss: 0.4301 - val_accuracy: 0.8040
Epoch 46/100
313/313 [==============================] - 13s 43ms/step - loss: 0.4001 - accuracy: 0.8210 - val_loss: 0.4306 - val_accuracy: 0.8008
Epoch 47/100
313/313 [==============================] - 14s 43ms/step - loss: 0.4001 - accuracy: 0.8224 - val_loss: 0.4375 - val_accuracy: 0.7950
Epoch 48/100
313/313 [==============================] - 14s 43ms/step - loss: 0.3998 - accuracy: 0.8222 - val_loss: 0.4306 - val_accuracy: 0.8018
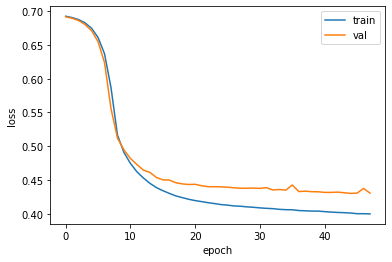
1 2 3 4 5 6 7 fig, ax = plt.subplots() ax.plot(history.history['loss' ]) ax.plot(history.history['val_loss' ]) ax.set_xlabel('epoch' ) ax.set_ylabel('loss' ) ax.legend(['train' , 'val' ]) plt.show()
Ref.) 혼자 공부하는 머신러닝+딥러닝 (박해선, 한빛미디어)