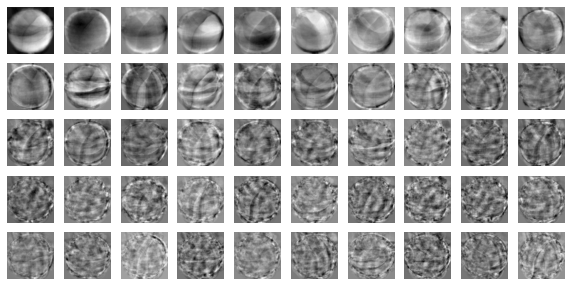
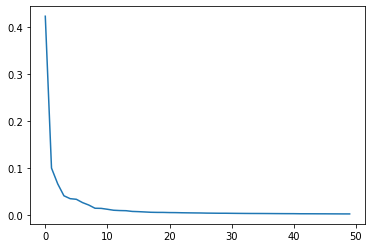
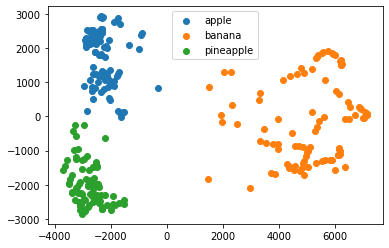
from sklearn.decomposition import PCA pca = PCA(n_components=50) pca.fit(fruits_2d) print(pca.components_.shape)
(50, 10000)
1 2 3 4 5 6 7 8 9 10 11 12 13 14
import matplotlib.pyplot as plt
defdraw_fruits(arr, ratio=1): n = len(arr) # the number of sample rows = int(np.ceil(n/10)) cols = n if rows < 2else10 fig, axs = plt.subplots(rows, cols, figsize=(cols*ratio, rows*ratio), squeeze=False) for i inrange(rows): for j inrange(cols): if i*10 + j < n: # n 개까지만 그립니다. axs[i, j].imshow(arr[i*10 + j], cmap='gray_r') axs[i, j].axis('off') plt.show()
0.9933333333333334
0.03829236030578613
/usr/local/lib/python3.7/dist-packages/sklearn/linear_model/_logistic.py:818: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
extra_warning_msg=_LOGISTIC_SOLVER_CONVERGENCE_MSG,
/usr/local/lib/python3.7/dist-packages/sklearn/linear_model/_logistic.py:818: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
extra_warning_msg=_LOGISTIC_SOLVER_CONVERGENCE_MSG,
/usr/local/lib/python3.7/dist-packages/sklearn/linear_model/_logistic.py:818: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
extra_warning_msg=_LOGISTIC_SOLVER_CONVERGENCE_MSG,