※ To prevent data leakage, make sure to convert the test set to the statistics learned from the training set. ※ Data leakage : containing the information you want to predict in the data used for model training
SGD Classifier
Fitting model
set 2 parameter in SGD Classifier
loss : specifying the type of loss function
max_iter : specifying the number of epochs to be executed
In the case of a multi-classification model, if loss is set as ‘log’, a binary classification model is created for each class.
0.773109243697479
0.775
/usr/local/lib/python3.7/dist-packages/sklearn/linear_model/_stochastic_gradient.py:700: ConvergenceWarning: Maximum number of iteration reached before convergence. Consider increasing max_iter to improve the fit.
ConvergenceWarning,
1 2 3 4
# partial_fit() : continue training one epoch per call sc.partial_fit(train_scaled, train_target) print(sc.score(train_scaled, train_target)) print(sc.score(test_scaled, test_target))
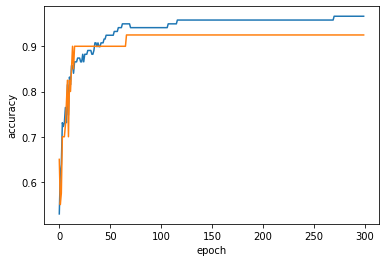
In the early stages of epoch, the scores of training sets and test sets are low because they are underfitting.
After epoch 100, the score difference between the training set and the test set gradually increases.
Epoch 100 appears to be the most appropriate number of iterations.
1 2 3 4 5 6
# SGD classifier stops by itself, if performance does not improve during a certain epoch. # tol = None : to repeat unconditionally untill max_iter sc = SGDClassifier(loss='log', max_iter=100, tol=None, random_state=42) sc.fit(train_scaled, train_target) print(sc.score(train_scaled, train_target)) print(sc.score(test_scaled, test_target))