Invoice ID Branch City Customer type Gender \
0 750-67-8428 A Yangon Member Female
1 226-31-3081 C Naypyitaw Normal Female
2 631-41-3108 A Yangon Normal Male
Product line Unit price Quantity Date Time Payment
0 Health and beauty 74.69 7 1/5/2019 13:08 Ewallet
1 Electronic accessories 15.28 5 3/8/2019 10:29 Cash
2 Home and lifestyle 46.33 7 3/3/2019 13:23 Credit card
1
sales.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 1000 entries, 0 to 999
Data columns (total 11 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Invoice ID 1000 non-null object
1 Branch 1000 non-null object
2 City 1000 non-null object
3 Customer type 1000 non-null object
4 Gender 1000 non-null object
5 Product line 1000 non-null object
6 Unit price 1000 non-null float64
7 Quantity 1000 non-null int64
8 Date 1000 non-null object
9 Time 1000 non-null object
10 Payment 1000 non-null object
dtypes: float64(1), int64(1), object(9)
memory usage: 86.1+ KB
Product line
Electronic accessories 170
Fashion accessories 178
Food and beverages 174
Health and beauty 152
Home and lifestyle 160
Sports and travel 166
Name: Quantity, dtype: int64
Product line
Electronic accessories 971
Fashion accessories 902
Food and beverages 952
Health and beauty 854
Home and lifestyle 911
Sports and travel 920
Name: Quantity, dtype: int64
1 2
print(sales.groupby(by=["Branch","Customer type"])['Quantity'].sum()) print(type(sales.groupby(by=["Branch","Customer type"])['Quantity'].sum())) # Series 객체
Branch Customer type
A Member 964
Normal 895
B Member 924
Normal 896
C Member 897
Normal 934
Name: Quantity, dtype: int64
<class 'pandas.core.series.Series'>
Branch Payment Quantity
0 A Cash 572
1 A Credit card 580
2 A Ewallet 707
3 B Cash 628
4 B Credit card 599
5 B Ewallet 593
6 C Cash 696
7 C Credit card 543
8 C Ewallet 592
<class 'pandas.core.frame.DataFrame'>
(-34.715, 145.525)
Series([], Name: Unit price, dtype: float64)
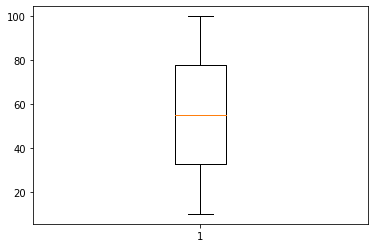
1 2
import matplotlib.pyplot as plt plt.boxplot(sales['Unit price'])
{'boxes': [<matplotlib.lines.Line2D at 0x7fefce5f93d0>],
'caps': [<matplotlib.lines.Line2D at 0x7fefce5fe3d0>,
<matplotlib.lines.Line2D at 0x7fefce5fe910>],
'fliers': [<matplotlib.lines.Line2D at 0x7fefce605410>],
'means': [],
'medians': [<matplotlib.lines.Line2D at 0x7fefce5fee90>],
'whiskers': [<matplotlib.lines.Line2D at 0x7fefce5f9910>,
<matplotlib.lines.Line2D at 0x7fefce5f9e50>]}